
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
一、环境说明
个人理解:
zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoop和hdfs整合集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下:
IP 角色
192.168.152.39 master 192.168.152.29 slave 192.168.152.45 slave2三个节点均使用CentOS 6.7系统,为了便于维护,集群环境配置项最好使用相同用户名、用户密码、相同Hadoop、Hbase、zookeeper目录结构。
注:
主机名和角色最好保持一致,如果不同也没关系,只需要在/etc/hosts中配置好对应关系即可 可以通过编辑/etc/sysconfig/network文件来修改 hostname软件包下载准备:
hadoop-2.7.3.tar.gz hbase-1.2.5-bin.tar.gz zookeeper-3.4.6.tar.gz jdk-8u101-linux-x64.tar.gz因为是测试环境此次都使用root来操作,如果是生产环境建议使用其他用户如hadoop,需要给目录授权为hadoop
chown -R hadoop.hadoop /usr/hadoop-2.7.3
二、准备工作
2.1 安装JDK
在三台机器上配置JDK环境,下载jdk-8u101-linux-x64.tar.gz 文件解压:
tar -zxvf jdk-8u101-linux-x64.tar.gz 修改配置文件 vim /etc/profile:#JAVA_HOMEJAVA_HOME=/usr/java/jdk1.8.0_101JRE_HOME=/usr/java/jdk1.8.0_101/jre#PATH=$JAVA_HOME/bin:$PATH#export PATH=$PATH#hadoopHADOOP_HOME=/usr/hadoop-2.7.3#zookeeperZOOKEEPER_HOME=/usr/zookeeper-3.4.6PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$PATHexport PATH=$PATH
在其他两台机器中同样安装java
然后重新加载配置文件使之生效:
# source /etc/profile2.2 添加Hosts映射关系
分别在三个节点上添加hosts映射关系:
# vim /etc/hosts
添加的内容如下:192.168.152.39 master192.168.152.29 slave192.168.152.45 slave2
2.3 集群之间SSH无密码登陆
CentOS默认安装了ssh,如果没有你需要先安装ssh 。
集群环境的使用必须通过ssh无密码登陆来执行,本机登陆本机必须无密码登陆,主机与从机之间必须可以双向无密码登陆,从机与从机之间无限制。
2.3.1 设置master无密码自动登陆slave1和slave2
主要有三步:
①生成公钥和私钥 ②导入公钥到认证文件 ③更改权限# ssh-keygen -t rsa# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys# chmod 700 ~/.ssh && chmod 600 ~/.ssh/*
测试,第一次登录可能需要yes确认,之后就可以直接登录了:
# ssh master
# ssh slave1 # ssh slave2scp ~/.ssh/id_rsa.pub root@192.168.152.29:/root
在29的机器上执行:cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
对于 slave1 和 slave2,进行无密码自登陆设置,操作同上。
也有个快捷的操作方式,当所有的服务器都ssh-keygen -t rsa生成公钥后,在master上操作无密码登陆master/slave1/slave2成功后,直接拷贝给其他主机即可三、Hadoop集群安装配置
这里会将hadoop、hbase、zookeeper的安装包都解压到/usr文件夹下,并重命名
安装目录如下: /usr/hhadoop-2.7.3 /usr/hbase-1.2.5 /usr/zookeeper-3.4.63.1 修改hadoop配置
配置文件都在/usr/hadoop-2.7.3/etc/hadoop/目录下
3.1.1 core-site.xml
fs.default.name hdfs://master:9000 io.file.buffer.size 131072 hadoop.tmp.dir /data/hadoop
3.1.2 hadoop-env.sh
添加JDK路径,如果不同的服务器jdk路径不同需要单独修改:
export JAVA_HOME=/usr/java/jdk1.8.0_1013.1.3 hdfs-site.xml
dfs.replication 2 dfs.permissions false
3.1.4 mapred-site.xml
# mv mapred-site.xml.template mapred-site.xml
mapreduce.framework.name yarn
3.1.6 yarn-site.xml
yarn.resourcemanager.hostname master yarn.nodemanager.aux-services mapreduce_shuffle
3.1.5 修改slaves文件,localhost改为
# cat /data/yunva/hadoop-2.7.3/etc/hadoop/slaves
slave1 slave2注意:三台机器上都进行相同的配置,都放在相同的路径下(如果jdk路径不同需要单独修改)
使用scp命令进行从本地到远程(或远程到本地)的轻松文件传输操作:scp -r /usr/hadoop-2.7.3/ slave1:/usr
scp -r /usr/hadoop-2.7.3/ slave2:/usr3.2 启动hadoop集群
进入master的/data/yunva/hadoop-2.7.3/目录,执行以下操作:
# bin/hadoop namenode -format 格式化namenode,第一次启动服务前执行的操作,以后不需要执行。 然后启动hadoop: # sbin/start-all.sh 通过jps命令能看到除jps外有3个进程: # jps30613 NameNode
30807 SecondaryNameNode 887 Jps 30972 ResourceManager四、ZooKeeper集群安装配置
可参考 centos6.5环境下zookeeper-3.4.6集群环境部署及单机部署详解http://blog.csdn.NET/reblue520/article/details/52279486
https://my.oschina.net/duanvincent/blog/914794
五、HBase集群安装配置
配置文件目录/usr/hbase-1.2.5/conf
5.1 hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_101 # 如果jdk路径不同需要单独配置
export HBASE_MANAGES_ZK=false 不使用默认的zookeeper
5.2 hbase-site.xml(保持一致)
hbase.rootdir hdfs://master:9000/hbase hbase.master master hbase.cluster.distributed true hbase.zookeeper.quorum slave,slave2 hbase.zookeeper.property.dataDir /usr/zookeeper-3.4.6/zookeeper-data
5.3 更改 regionservers
master
slave slave25.4 分发并同步安装包
将整个hbase安装目录都拷贝到所有slave服务器:
$ scp -r /usr/hbase-1.2.5 root@192.168.152.29:/usr
$ scp -r /usr/hbase-1.2.5 root@192.168.152.45:/usr六、启动集群
1. 启动ZooKeeper
/usr/zookeeper-3.4.6/bin/zkServer.sh start
2. 启动hadoop
/usr/hadoop-2.7.3/sbin/start-all.sh
3. 启动hbase
/usr/hbase-1.2.5/bin/start-hbase.sh
4. 启动后,master上进程和slave进程列表
[root@master ~]# jpsJpsSecondaryNameNode # hadoop进程NameNode # hadoop master进程ResourceManager # hadoop进程HMaster # hbase master进程ZooKeeperMain # zookeeper进程[root@slave1 ~]# jpsJpsZooKeeperMain # zookeeper进程DataNode # hadoop slave进程HRegionServer # hbase slave进程
5. 进入hbase shell进行验证
[root@master bin]# ./hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/usr/hbase-1.2.5/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/usr/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]HBase Shell; enter 'help' for list of supported commands.Type "exit " to leave the HBase ShellVersion 1.2.5, rd7b05f79dee10e0ada614765bb354b93d615a157, Wed Mar 1 00:34:48 CST 2017hbase(main):001:0> status1 active master, 0 backup masters, 3 servers, 0 dead, 1.0000 average loadhbase(main):002:0>
6. 进入zookeeper shell进行验证
如果访问默认的http管理端口页面可以看到集群的情况
hadoop: http://IP:8088/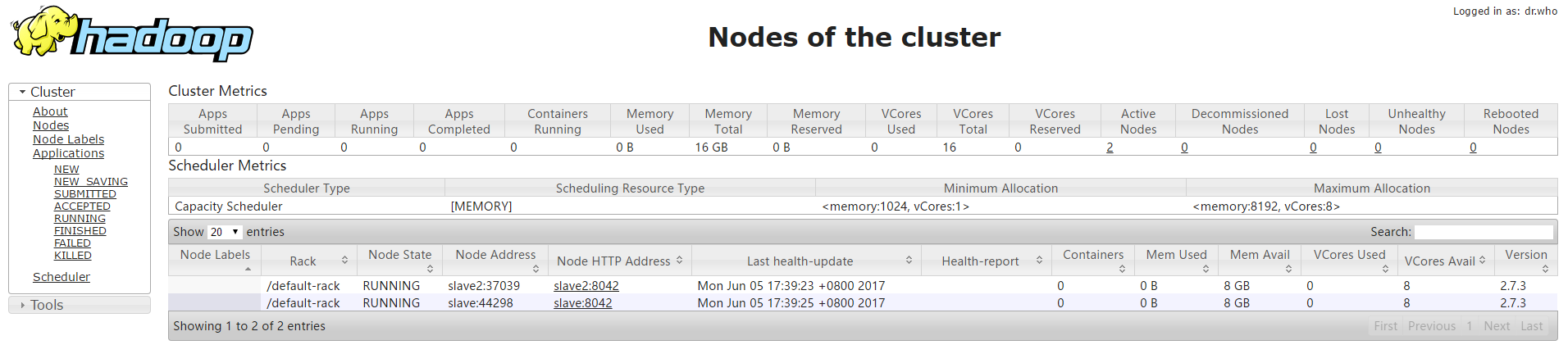
hbase:
http://IP:16010/master-status
hdfs:
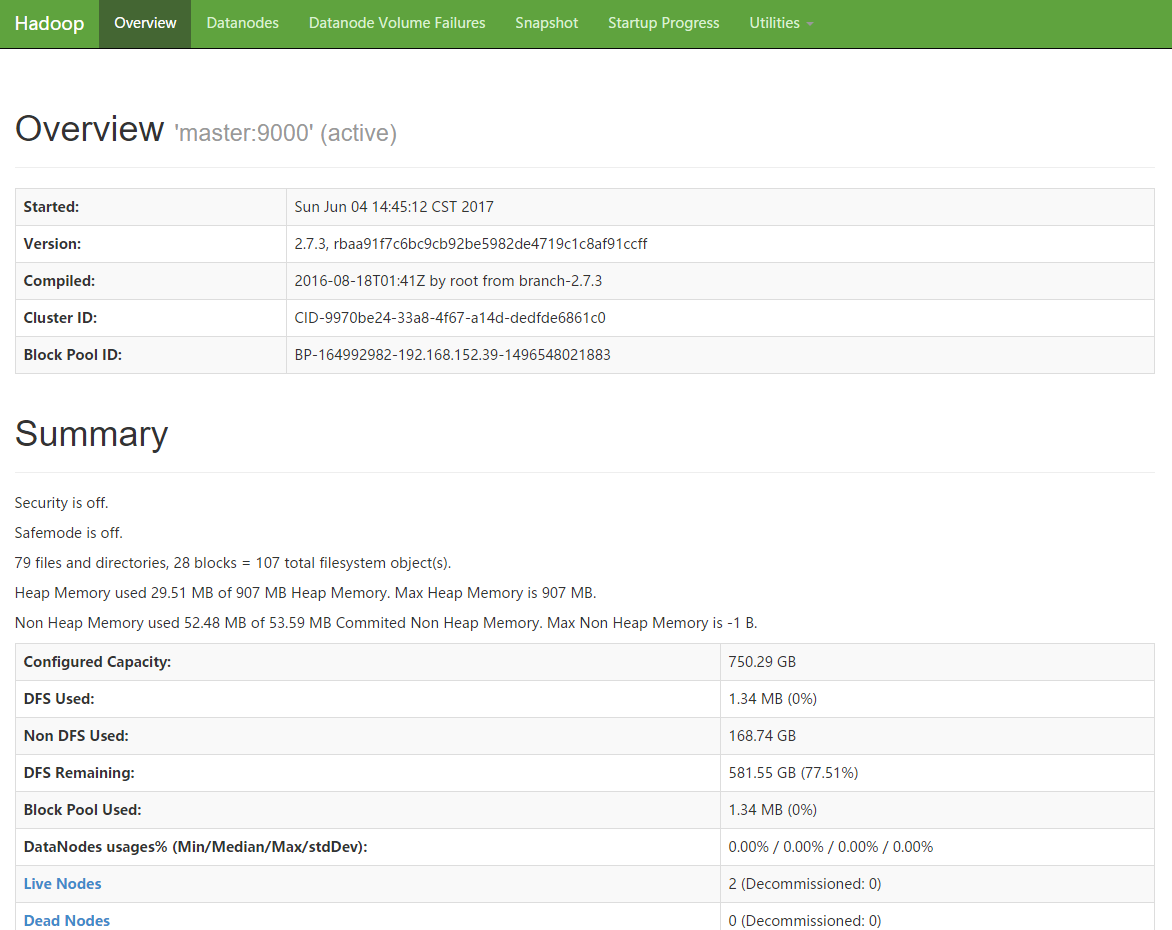
http://IP:50070/dfshealth.html#tab-overview
org.apache.hadoop.ipc.Client: Retrying connect to server异常的解决
检查发现是DataNode一直连接不到NameNode。
检查各个节点在etc/hosts中的配置是否有127.0.1.1 xxxxxx。如果有把其屏蔽或者删除,重启各节点即可。 原因:127.0.1.1是ubuntu中的本地回环。这个造成了hadoop解析出现问题。这个设置应该是在做伪分布式的hadoop集群的时候,留下来的。